

How to Build a Scalable Data Engineering Platform for Multi-Source Analytics
Modern analytics depends on how well data is engineered long before it reaches dashboards. As organizations pull data from cloud apps, internal systems, and external vendors, complexity increases and reliability often suffers. A scalable data engineering platform provides the foundation needed to unify multi-source data, enforce consistency, and deliver analytics teams can trust. This guide explains how to design such a platform with scale, quality, and long-term adaptability in mind.
Why Data Engineering Architecture Defines Analytics Outcomes
Modern enterprises depend on analytics for operational efficiency and strategic decision-making. Yet many struggle with inconsistent data quality and unreliable pipelines. Industry research shows that data professionals spend roughly 40% of their time evaluating or checking data quality issues, and poor data quality negatively affects approximately 26% of their company’s revenue. This illustrates how pervasive and costly data reliability problems can be, making scalable data engineering a mission-critical capability.
Many organizations struggle because their data platforms were built incrementally. Pipelines were added to meet immediate needs, not long-term scale. Over time, this leads to fragile workflows, inconsistent metrics, and slow delivery. Industry research consistently shows that data teams spend a significant portion of their time resolving data quality and pipeline reliability issues, which directly limits their ability to generate business value.
A scalable data engineering platform addresses these challenges by introducing structure, discipline, and repeatability into how data is ingested, transformed, and delivered.
What Is a Scalable Data Engineering Platform?
A scalable data engineering platform is an enterprise architecture that reliably moves data from diverse sources into analytics-ready formats while supporting growth in data volume, usage, and complexity.
Scalability does not only refer to handling more data. It also means the platform can adapt to new vendors, evolving schemas, and changing reporting requirements without repeated rework. From a business perspective, scalability ensures analytics remains dependable as the organization grows.
In practice, scalable platforms emphasize standardization, automation, and clear separation of responsibilities across the data lifecycle.
Why Multi-Source Data Environments Break Down?
Multi-source environments introduce complexity at every stage of the analytics pipeline. External vendors often deliver data with inconsistent naming conventions, incomplete records, and unpredictable refresh cycles. Internal systems may evolve independently, introducing breaking schema changes over time.
Without a centralized engineering approach, teams compensate by embedding logic directly into reports and dashboards. This creates duplication and divergence. Metrics that appear identical may be calculated differently across teams, leading to conflicting insights and reduced trust.
The root cause is rarely tooling. It is the absence of a coherent data engineering process that standardizes how data is handled across sources.
Core Principles of Scalable Data Engineering Architecture
Successful data platforms are built on a small set of foundational principles that guide every design decision.
Modularity
Each stage of the data lifecycle is isolated. Ingestion, transformation, and analytics layers are designed to change independently. This prevents upstream changes from breaking downstream reports.
Reusability
Business logic is implemented once and reused everywhere. This eliminates the need to redefine metrics across dashboards and reduces maintenance overhead.
Transparency
All transformations are version-controlled, documented, and traceable. Engineers and analysts can understand where data comes from and how it changes.
Resilience
Failures are expected and designed for. Pipelines detect errors early, recover gracefully, and surface issues before they impact stakeholders.
These principles ensure platforms remain manageable as they scale.
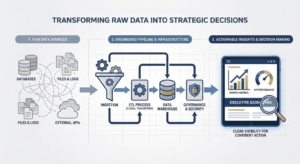
Designing Reliable Data Ingestion Pipelines
Data ingestion is the entry point for all analytics workflows. Poor ingestion design introduces latency, missing data, and silent failures that propagate throughout the platform.
A robust ingestion process starts by classifying data sources based on how they are used.
Common ingestion patterns include:
- Continuous ingestion for operational systems where freshness is critical
- Scheduled batch ingestion for periodic vendor data
- Incremental loading strategies that capture only changed records
From an engineering standpoint, raw data should be ingested with minimal transformation. Preserving source fidelity allows teams to reprocess data when business logic changes and provides traceability for audits.
Practical tip:
Always log ingestion metadata such as load time, record counts, and source versions. These signals are invaluable when troubleshooting downstream issues.
Layered Data Architecture for Analytics at Scale
Layered architecture introduces order into complex data ecosystems by separating concerns.
Raw and Staging Layer
This layer stores ingested data with minimal modification. The goal is accuracy and traceability, not usability. Data engineers rely on this layer to validate source completeness and diagnose upstream issues.
Transformation and Business Logic Layer
This layer applies standardized transformations. Schemas are normalized, data types are enforced, and business rules are applied consistently across sources. Joins and calculations are performed here rather than inside reports.
Analytics Layer
The final layer exposes curated datasets designed specifically for analytics consumption. These tables prioritize clarity, performance, and consistency over flexibility.
This separation allows teams to evolve business logic without re-ingesting data or disrupting reporting.
Building Analytics-Ready Data Models
Analytics-ready models are designed for consumption, not storage. They reduce cognitive load for analysts and improve query performance.
Most enterprise platforms rely on dimensional modeling.
Fact tables capture measurable business events such as transactions, usage, or interactions.
Dimension tables provide descriptive context such as customer attributes, products, or time periods.
Star schema designs remain widely adopted because they simplify queries and enforce consistent metric definitions. Analysts spend less time writing complex joins and more time interpreting results.
Practical tip:
Define ownership for each fact table. Clear ownership ensures metric definitions remain stable as teams grow.
Making Data Quality and Observability Non-Negotiable
As platforms scale, manual validation becomes impossible. Data quality must be automated and continuously enforced.
Effective platforms implement tests that validate assumptions such as uniqueness, completeness, and referential integrity. These tests run as part of every data refresh and block flawed data from reaching analytics layers.
Observability complements testing by monitoring freshness, volume changes, and anomaly patterns across datasets. Together, these capabilities provide early warnings and reduce time to resolution.
Practical tip:
Alert on data freshness rather than pipeline failures alone. Late data is often more damaging than missing data.
Supporting Multiple Reporting and Analytics Use Cases
A scalable platform serves multiple audiences without duplicating logic.
Executives rely on consistent KPIs for strategic decisions. Operations teams require detailed views for day-to-day management. External stakeholders expect accurate and timely reporting.
By centralizing transformations and exposing standardized models, the platform ensures all users operate from the same definitions. This alignment eliminates reconciliation efforts and strengthens trust in analytics outputs.

Optimizing Data Warehouses for Performance and Cost
The data warehouse is where analytics performance and cost intersect. Poor optimization results in slow queries and unpredictable spend.
Performance optimization involves thoughtful table design, appropriate partitioning, and workload isolation. Cost optimization requires aligning compute usage with demand and monitoring storage growth over time.
Practical tip:
Review query patterns regularly. Most warehouse costs are driven by a small number of inefficient queries.
Designing for Growth and Change
Scalable platforms anticipate change. New data sources, evolving schemas, and additional analytics use cases should be expected rather than treated as exceptions.
Reusable transformation patterns, schema evolution handling, and automated deployment pipelines allow teams to adapt quickly without destabilizing existing workflows.
This forward-looking design significantly reduces long-term engineering effort and risk.
Security, Governance, and Auditability
Enterprise platforms must enforce governance without restricting access to insights.
Role-based access control ensures users only see authorized data. Lineage tracking and version history provide visibility into how data is created and modified. These capabilities support compliance requirements while maintaining transparency.
Governance embedded into the platform builds confidence across technical and business teams.
Measuring the Success of a Data Engineering Platform
Scalability must be measurable. Technical metrics indicate platform health, while business metrics reflect impact.
Key indicators include:
- Data freshness and reliability
- Time required to onboard new data sources
- Query performance under concurrent usage
- Adoption of analytics across teams
These metrics help organizations quantify the value of data engineering investments.
Conclusion: Turning Data Engineering into a Strategic Capability
Scalable data engineering platforms do more than support analytics. They enable organizations to respond faster, operate with confidence, and adapt to change without friction.
When architecture, quality, and governance are treated as first-class concerns, data engineering becomes a long-term competitive advantage rather than a recurring challenge.
FAQs
1. What makes a data engineering platform scalable?
A scalable data engineering platform is built on a layered architecture with reusable transformations, automated data quality checks, and the flexibility to onboard new data sources without major redesign. This approach supports growth while keeping systems maintainable.
2. Why do analytics platforms fail in multi-source environments?
Analytics platforms often fail when data comes from multiple sources due to inconsistent schemas, duplicated transformation logic, and the absence of centralized governance. These issues lead to conflicting metrics and unreliable insights.
3. How does data modeling improve analytics reliability?
Data modeling improves reliability by enforcing consistent definitions for metrics and dimensions. Well-structured models reduce ambiguity, align teams on a single source of truth, and increase confidence in reports and dashboards.
4. What role does data observability play in analytics?
Data observability helps detect anomalies, freshness issues, and pipeline delays early. By identifying problems before data is consumed, it prevents flawed or incomplete data from influencing business decisions.
5. How can organizations reduce analytics operational overhead?
Organizations can reduce operational overhead by centralizing data transformations, automating testing and validation, and designing platforms that scale predictably as data volumes and use cases grow.
6. What metrics should leaders track to evaluate data platforms?
Leaders should track data freshness, reliability, source onboarding speed, query performance, and overall business adoption to assess whether a data platform is delivering real value.


